Contato
Que tal agendarmos uma entrevista?!
Entre em contato pelo WhatsApp ou e-mail abaixo.
Transformando dados em insights valiosos para decisões mais estratégicas e eficientes.
Atuo há cinco anos na área de análise de dados, com os últimos três anos dedicados ao planejamento na Quero-Quero. Minha experiência inclui análise de indicadores financeiros e operacionais, modelagem de dados, desenvolvimento de ferramentas de automação e criação de dashboards interativos para suporte à decisão estratégica. Além disso, migrei fluxos de trabalho de VBA para Python e SQL, implementando processos de ETL que reduziram erros operacionais e aumentaram a eficiência.
Possuo mestrado em Biologia Molecular com ênfase em Bioinformática, onde desenvolvi habilidades em modelagem estatística, programação em Python e análise de grandes volumes de dados científicos.

Automação de rotinas, migração de ferramentas VBA para Python, desenvolvimento de ferramentas, modelagem de dados e criação de dashboards interativos.
Principais bibliotecas: NumPy, Pandas, OS, Selenium, Streamlit, Seaborn.
85%Conexão e manipulação de dados em PostgreSQL (PG) e Microsoft Fabric. Experiência com CTEs e queries otimizadas para melhor performance.
80%Criação de tabelas dinâmicas, dashboards interativos, VBA e integração com outras fontes de dados para automação de relatórios.
75%Aprendendo infraestrutura como código (IaC) com Terraform e uso de Docker para deploy na nuvem (AWS).
55%Minha trajetória profissional reflete a evolução e consolidação de competências em análise de dados, desde a automação de processos até o desenvolvimento de dashboards e modelagem de dados para suporte estratégico.
Atuo transformando dados brutos em insights acionáveis para decisões estratégicas, otimizando processos operacionais e financeiros, automatizando relatórios e aprimorando a acessibilidade dos dados entre as equipes.
Com sólida experiência em Python, SQL, VBA e Microsoft Fabric, continuo aprimorando a abordagem baseada em dados da empresa, garantindo que os insights se traduzam em ações estratégicas para aumentar a eficiência e a lucratividade.
Condução de projetos de pesquisa utilizando Python, Linux e técnicas de análise estatística. Desenvolvi pipelines para processamento de dados biológicos e apliquei metodologias de análise, culminando na defesa da dissertação e publicação de artigo científico.
Minha formação acadêmica complementa minha experiência profissional, proporcionando uma base sólida em análise de dados e métodos estatísticos.
Pesquisa focada na análise de grandes volumes de dados científicos, modelagem de dados e programação em Python, contribuindo para a defesa da dissertação e publicação de um artigo científico.
Formação teórica e prática em ciências biológicas, que serviu de base para o desenvolvimento de pesquisas interdisciplinares e a aplicação de métodos analíticos em projetos científicos.
Atualmente, trabalho em projetos estratégicos dentro da empresa, focando em automação, análise de dados e otimização de processos. No entanto, devido a políticas de confidencialidade, esses projetos não podem ser compartilhados publicamente. Se houver interesse em saber mais sobre minha experiência e os desafios que enfrento no dia a dia, ficarei feliz em discuti-los em uma entrevista!
Segue abaixo alguns dos projetos desenvolvidos (no acesso aos dashboards é necessário aguardar enquanto ele carrega).
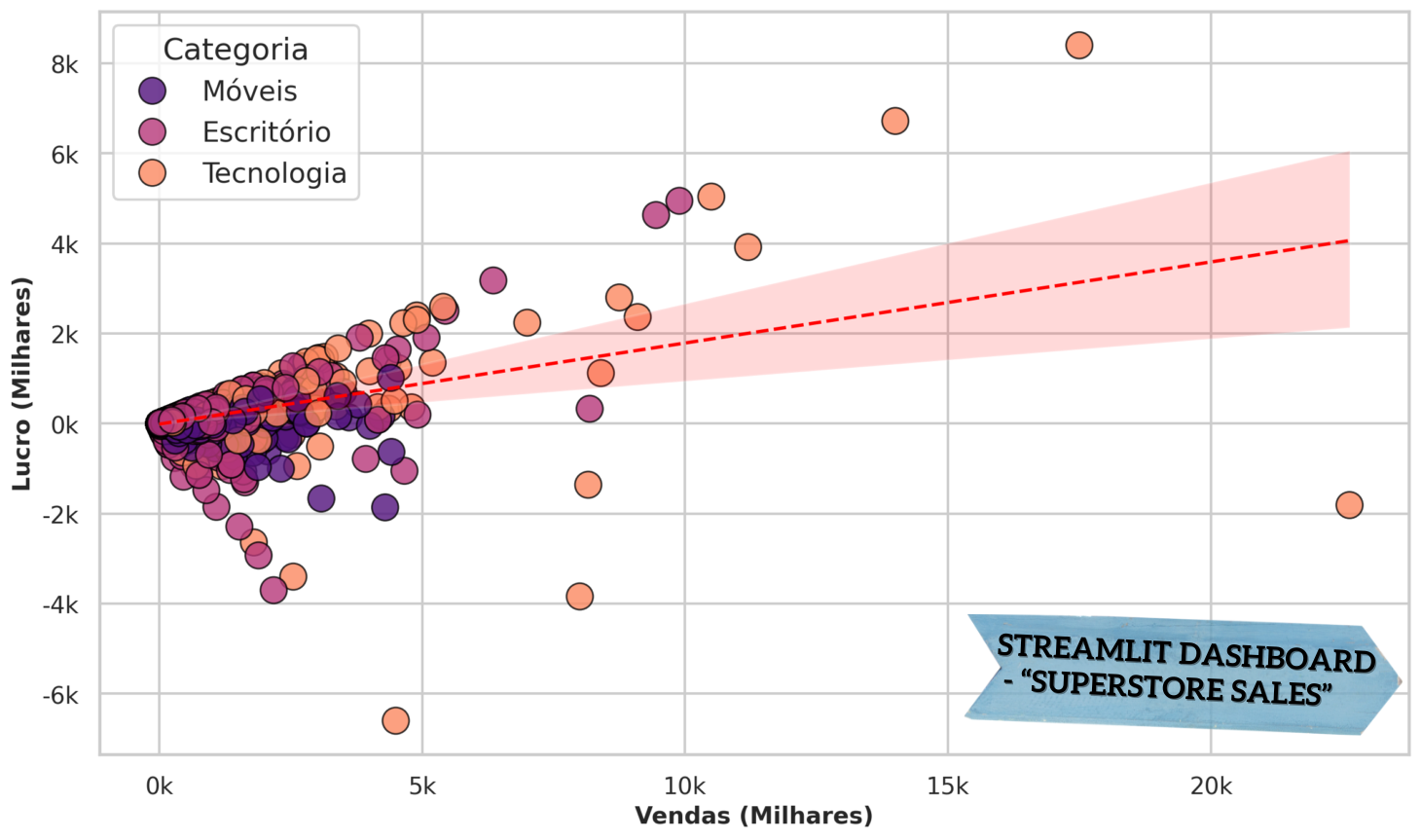
Este dashboard fornece insights estratégicos para otimização das operações de varejo (venda, lucro, margem, desconto, clusterização, segmentação de clientes e regionalização).

Sua empresa importa produtos por portos ligados a rios estratégicos. Alguns desses produtos possuem alta sazonalidade de venda no verão. No entanto, existe um histórico de redução significativa na cota dos rios devido à seca, o que pode inviabilizar o transporte por algumas rotas. Diante disso, é essencial monitorar os níveis de água dos rios e projetar tendências futuras para antecipar decisões estratégicas e mitigar riscos.
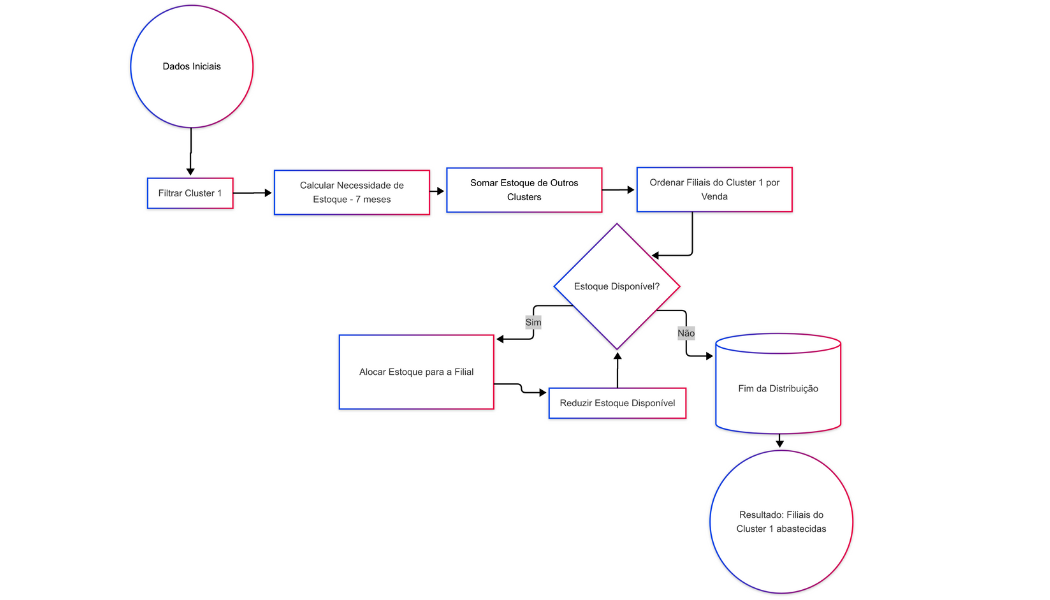
O código tem como objetivo redistribuir o estoque de materiais entre filiais, priorizando as filiais do Cluster 1 (com maior demanda) e retirando o estoque das filiais com Cluster inferior (Cluster 2 e acima).
O sistema calcula a necessidade de estoque de cada filial, comparando o estoque atual e o necessário para atender uma demanda de 7 meses, e então realiza a redistribuição a partir de estoques de outras filiais.
Além disso, o código implementa um loop de redistribuição sequencial, onde o estoque total disponível (no caso das filiais acima do 1) vai sendo diminuído à medida que as quantidades são redistribuídas para as filiais do cluster 1, garantindo que o estoque disponível seja alocado de forma eficiente.
Análise de performance comercial, automação de processos e visualização de dados.
Saiba maisAvaliação de métricas financeiras, giro de estoque, previsão de demanda (entre outros KPI's) para insights estratégicos.
Substituição de fluxos VBA por Python e SQL, reduzindo tempo de processamento e melhorando a eficiência.
Criação de dashboards interativos e relatórios dinâmicos para tomada de decisão baseada em dados.
Otimização de consultas SQL e processos ETL para extração e transformação eficiente dos dados.
Entre em contato pelo WhatsApp ou e-mail abaixo.